
Why does a process need to have a port number for Internet communication?
I will use a server instance to illustrate why. Let us say I create a web application and I set it up with Nginx, but I do not put the port number. Without port number, the app will not be able to send the data, since Nginx is just pointing at it but not using a port to be able to use it. Once I assign a port number, let us say 80, Nginx will use that port to communicate to the server base and send that data to that port. Also when we connect my app, we connect to its IP address, but my app may be running x amount of processes, such as Auth, file server, emails, etc, and with the port number we can identify the service that we are trying to connect. If IPs are what reference the location of my app (let’s say street address), ports are what allow access to the data to be in and out (let’s say the door of the house), and since many processes may be running in the same port we have to have a way to know which process goes where. Since ports are always associated with IP addresses, we can send the information accordingly, let us say for instance HTTP/= port 443 for static web pages. Therefore, processes need to have ports that they can use these are associated to IPs for internet communication.
Compare the client-server with P2P architecture. What are the pros/cons of each architecture?
P2P Advantages
- No need for a network operating system
- Does not need an expensive server because individual workstations are used to access the files • No need for specialist staff such as network technicians because each user sets their own permissions as to which files they are willing to share. 3. Much easier to set up than a client-server network - does not need specialist knowledge.
- If one computer fails it will not disrupt any other part of the network. It just means that those files aren't available to other users at that time.
P2P Disadvantages
- Because each computer might be being accessed by others it can slow down the performance for the user.
- Files and folders cannot be centrally backed up.
- Files and resources are not centrally organized into a specific 'shared area'. They are stored on individual computers and might be difficult to locate if the computer's owner doesn't have a logical filing system.
- Ensuring that viruses are not introduced to the network is the responsibility of each individual user.
- There is little or no security besides the permissions. Users often don't need to log onto their workstations.
Client-Server Advantages
- All files are stored in a central location.
- Network peripherals are controlled centrally.
- Backups and network security is controlled centrally.
- Users can access shared data which is centrally controlled
Client-Server Disadvantages
- A specialist network operating system is needed.
- The server is expensive to purchase.
- Specialist staff such as a network manager is needed.
- If any part of the network fails a lot of disruption can occur
Let the following figure be the schematic view of a communication network between two end-systems A and B.

Assume that the nodal processing delay is negligible. Also, assume that the link between A and the router is 10,000 meters long and the link between B and the router is 20,000 meters long. If the propagation speed in both links is 200,000,000 m/sec, answer the following questions:
a. What is the total propagation delay for a packet sent from A to B? (Hint: propagation delay of a link is directly proportional to its length and reversely proportional to its propagation speed).
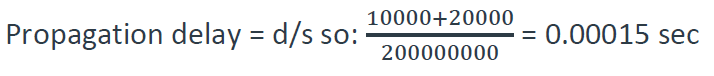
b. Calculate the total transmission delay of a 50MB file sent from A to B (Hint: 1MB is 223 bits and 1Mb/sec is 106 bits/sec)

c. Is the queuing delay of sending a file from A to B equal to the queuing delay of sending the same file from B to A? Explain your answer.
Queuing delay is the time a job waits in a queue until it can be executed. It’s the delay that a packet spends time in queue at the node while waiting for other pockets to be transmitted. So, there is a higher delay from B to A.
