Let me show you step by step with images, how to setup a working to-do app using a Serverless HTTP API with DynamoDB and S3 bucket. I've followed this myself so everything is up to date and easy to follow :)
What I'll build
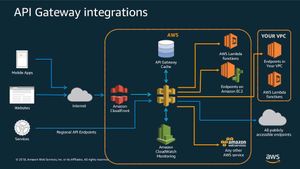
The goal is to build an infrastructure that allows to connect many devices to an API so I can handle CRUD operations through it. It must be secured, fast, flexible and easy to re-implement on another project by following this guide. This is a visual representation (I may expand it):
It starts by taking HTTP requests through an API Gateway endpoint, then processing those requests with AWS Lambda before reading or writing data in a DynamoDB table and returning a result back through API Gateway.
What I'll use:
- AWS DynamoDB as the database
- AWS Lambda to create functions that will read and write from/to the database
- AWS API Gateway to create the HTTP API that the apps will use
- AWS S3 to host the apps data such as images
HTTP APIs are a newer version of REST API.
HTTP APIs have lower latency and lower cost than REST APIs
HTTP APIs were designed from the ground up and thus, are supposed to be faster and cheaper than REST APIs.
The first version of API Gateway was introduced in 2015. The first version of the API Gateway is referred to as REST APIs which is probably the most common usage of the API Gateway.
Why I chose not to use the serverless framework
If you are somewhat familiar with serverless you know it can be extremely useful, however I have my own opinion:
- What if the team stops supporting the open source project?
- What if I deploy and some underlying value not define changes my prod configuration? Yes, it can be tested but not everything and that also adds more work and complexity.
- Community takes forever to respond or don't do it at all
Here's a clear example. A full project with more than 53 contributors lost the maintainer and have zero activity to support it from community (only issues was created in repo).
Definitions
Before start clicking buttons we need to understand what tools we'll use. This is essential.
Amazon API Gateway
To the point: Create, maintain, and secure APIs at any scale
Detailed: It's is a managed service that allows developers to define the HTTP endpoints of a REST API or a WebSocket API and connect those endpoints with the corresponding backend business logic. It also handles authentication, access control, monitoring, and tracing of API requests.
Many Serverless applications use Amazon API Gateway, which conveniently replaces the API servers with a managed serverless solution.
Here is a feature summary of what is available today.
You can contact support here.
DynamoDB is a fully-managed NoSQL database that stores the data in key-value pairs, like a JSON object. It's a fast and flexible service for any scale.
There are no schemas so every record can have a different structure. The only restriction is that the field(s) defined as the partition key must be present in all the records.
DynamoDB gives you a lot of options. You can learn more about it in the developer guide.
AWS Lambda
To the point: Run code without thinking about servers or clusters. Only pay for what you use.
Detailed: With Lambda, you can run code for virtually any type of application or backend service - all with zero administration. Just upload your code as a ZIP file or container image, and Lambda automatically and precisely allocates compute execution power and runs your code based on the incoming request or event, for any scale of traffic.
You can set up your code to automatically trigger from 140 AWS services or call it directly from any web or mobile app. You can write Lambda functions in your favorite language (Node.js, Python, Go, Java, and more) and use both serverless and container tools, such as AWS SAM or Docker CLI, to build, test, and deploy your functions.
Lambda proxy integration is a lightweight, flexible API Gateway API integration type that allows you to integrate an API method – or an entire API – with a Lambda function. The Lambda function can be written in any language that Lambda supports. Because it's a proxy integration, you can change the Lambda function implementation at any time without needing to redeploy your API.
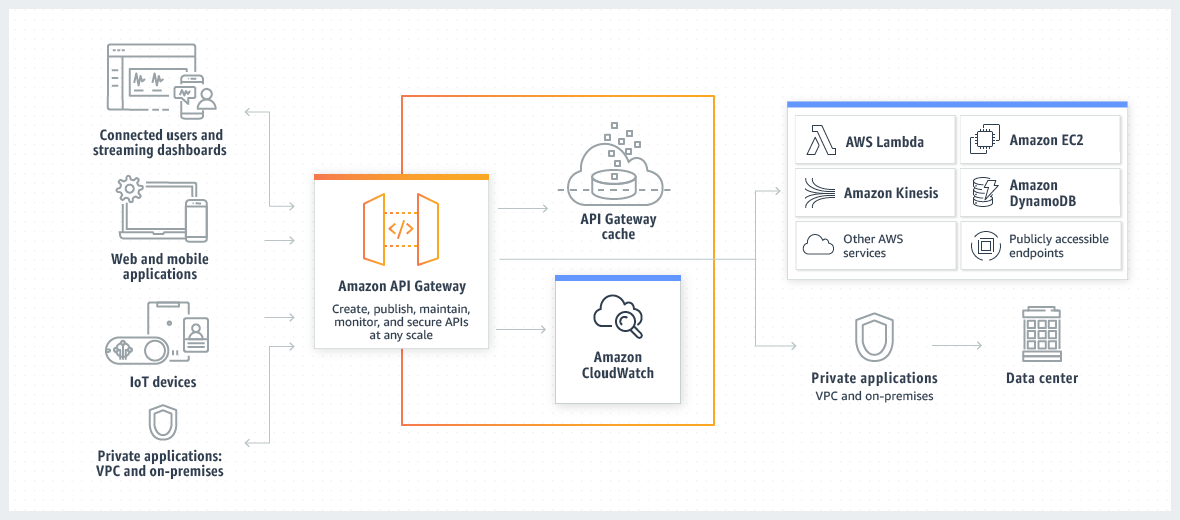
What is API Gateway good for?
The main use case for Amazon API Gateway is in building serverless HTTP APIs.
HTTP APIs enable you to create RESTful APIs with lower latency and lower cost than REST APIs.
You can use HTTP APIs to send requests to AWS Lambda functions or to any publicly routable HTTP endpoint.
For example, you can create an HTTP API that integrates with a Lambda function on the backend. When a client calls your API, API Gateway sends the request to the Lambda function and returns the function's response to the client.
HTTP APIs support OpenID Connect and OAuth 2.0 authorization. They come with built-in support for cross-origin resource sharing (CORS) and automatic deployments.
Amazon API Gateway pricing
With Amazon API Gateway, you only pay when your APIs are in use. There are no minimum fees or upfront commitments. For HTTP APIs and REST APIs, you pay only for the API calls you receive and the amount of data transferred out. There are no data transfer out charges for Private APIs. However, AWS PrivateLink charges apply when using Private APIs in API Gateway. API Gateway also provides optional data caching charged at an hourly rate that varies based on the cache size you select. For WebSocket APIs, you only pay when your APIs are in use based on number of messages sent and received and connection minutes.
The API Gateway free tier includes one million HTTP API calls, one million REST API calls, one million messages, and 750,000 connection minutes per month for up to 12 months.
Why is API Gateway an essential part of the Serverless ecosystem?
When using API Gateway together with other AWS services, it’s possible to build a fully functional customer-facing web application without maintaining a single server yourself.
This brings the advantages of the serverless model—scalability, low maintenance, and low cost due to low overhead—to mainstream web applications.
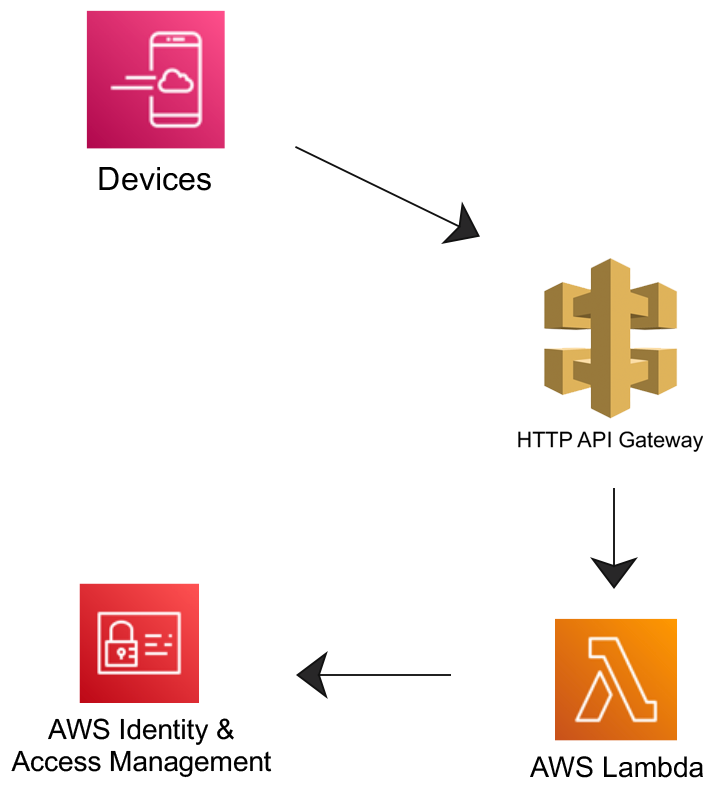
Plan Architecture
This architecture was inspired by Philips ecosystem, I think they are doing an excellent job and I like the overall setup. Here's how mine looks:
- Create a Lambda function using the AWS Lambda console
- Create an HTTP API using the API Gateway console
- Test your API.
Why Proxy integration?
HTTP proxy integration is a simple, powerful, and versatile mechanism to build an API that allows a web application to access multiple resources or features of the integrated HTTP endpoint, for example the entire website, with a streamlined setup of a single API method.
Let's Start! 👨🏻💻🔥
I'm going to be following this official tutorial. It doesn't show you there step by step, it's actually VERY confusing, that's why this guide exists in a more clear and concise way 🤓
Adding a layer of security
Before I start, I'm going to create a new User so I don't use my root user for common development.
Please refer to this AWS guide on how to create it.
To create give your computer and other services access to AWS, create a new access key.
Login in the AWS web with the user created at the begging of this guide and click on the name on the top right corner and select My Security Credentials (that link is for a specific region, choose yours correctly).
Once on the Security page, under Access keys for CLI, SDK, & API access click on Create Access Key, I recommend downloading it since you won't be able to access it again.
Step 1: Create a DynamoDB
DynamoDB gives you a lot of options. You can learn more about it in the developer guide, but for now, let's dive into creating a database for our API.
There are multiple ways of creating the DB, for example, going to DynamoDB and hit create table but it's better if we already have a model in mind so I recommend using NoSQL Workbench to model the data and then publish the database within the Workbench OR you could go to the DynamoDB page and copy the structure from the Workbench :)
- On the NoSQL Workbench create a new data model.
(Remember you can always go to the DynamoDB page after you publish it to see the changes.) - Now go to Data modeler and select your Data model, and click the + button to create a new Table.
- Table name:
SwiftyPlanner - Primary key:
PK(this is a generic name and works excellent for DynamoDB, as you use it you'll understand why) - Add sort key:
SK(again, generic name) - Now click on add table definition to create it. This is how it looks:
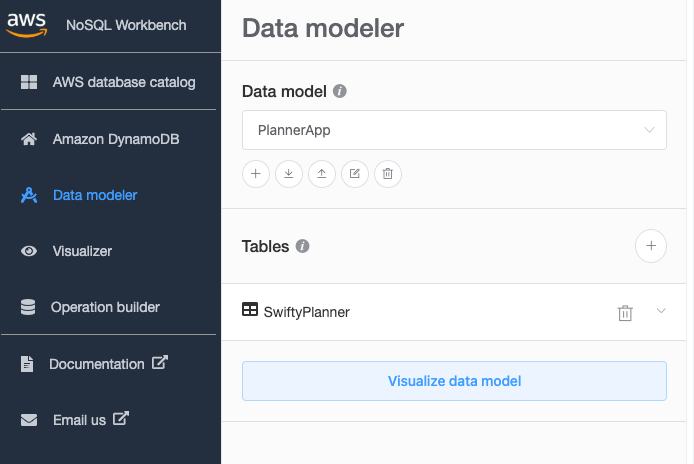
Now on Data modeler, click the SwiftyPlanner you just created and edit the table. Add the following atribute names:
username-> StringfirstName-> StringlastName-> Stringemail-> StringphoneNumber-> Stringbio-> String
You can add more, but that's the basics. In Visualizer you can now see this structure and add data.
At this point we have only created the model but not the actual database. Test around with the workbench placing some data and see if it doesn't complain and it's according to your needs. Once done, go to Visualizer and click on Commit to Amazon DynamoDB. Once the database is commited you can see it in Operation builder and also in the AWS DynamoDB page.
Once you commit your DB and see that it's already in AWS Cloud, you'll need something called ARN, so keep it handy, see image below.
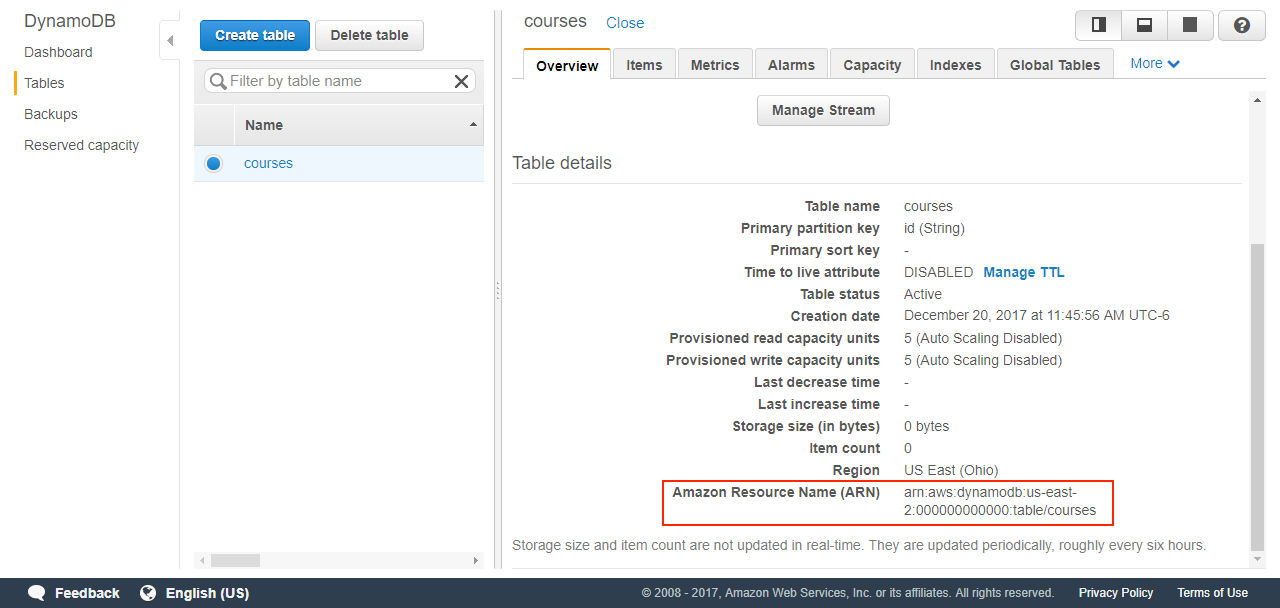
You can perform all CRUD operations from the Workbench, however to modify the model you'll have to do it in the web or submit again from the workbench.
How the DynamoDB & NoSQL Workbench works
Let's look at this example:

- The PK (partition key) has to be unique
- The SK (sort key) can change
I think this guy will explain it better so just watch it...
Step 2: Create an HTTP API Gateway
Create a simple HTTP API Gateway.
- Name:
SwiftyPlanner - Stages:
v1with autodeployment for now. - Don't attach any integration.
- Make sure you select Version
2.0
Step 3: Setup permissions
Let's create the CRUD operations using Lambda functions to communicate with DynamoDB (this is not the API yet)
For faster development I'll create 1 Role w/ 1 policy. For better granular security I would create new ones for each CRUD operation.
This is NOT the JSON payload that you sent through your HTTP request.
An HTTP request through the API Gateway gets transformed into aneventobject in the lambda function.
Policy
Go to Policies and click on Create Policy and copy the JSON from below (editing the resource name)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:CreateLogDelivery",
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogGroups",
"logs:DescribeLogStreams",
"logs:GetLogEvents",
"logs:FilterLogEvents",
"dynamodb:DeleteItem",
"dynamodb:GetItem",
"dynamodb:PutItem",
"dynamodb:Scan",
"dynamodb:UpdateItem"
],
"Resource": "<YOUR_ARN_FOR_THE_COURSES_TABLE>"
}
]
}Name it: users-planner-basic-crud-lambda-policy
Now do the same for the todos just change the table of the DB.
Name it: todos-planner-basic-crud-lambda-policy
Roles
- I'm going to create 1 different roles for each. Create a new role here.
- Select Lambda
- Look up
users-planner-basic-crud-lambda-policyrole and name it:users-planner-basic-crud-lambda-role - Do the same for the todos
Step 4: Create Lambda Function
A Lambda function is triggered by a so-called event source. An event source is an AWS service.

Go to the AWS Lambda page and create one:
- Use the
blueprint microservice-http-endpointlambda function as sample and click configure. - Name:
Swifty-Planner-API - Use existing role created above
- In
API Gateway triggerchoose your API,v1for Stage andOpenfor security. This will create a trigger so when I go in my Api gateway towww.xxxx.com/Swifty-Planner-APIit invokes my lambda function. Below I show how to remove theMyLambdaAPIpart of the URL. - This is how it should look:
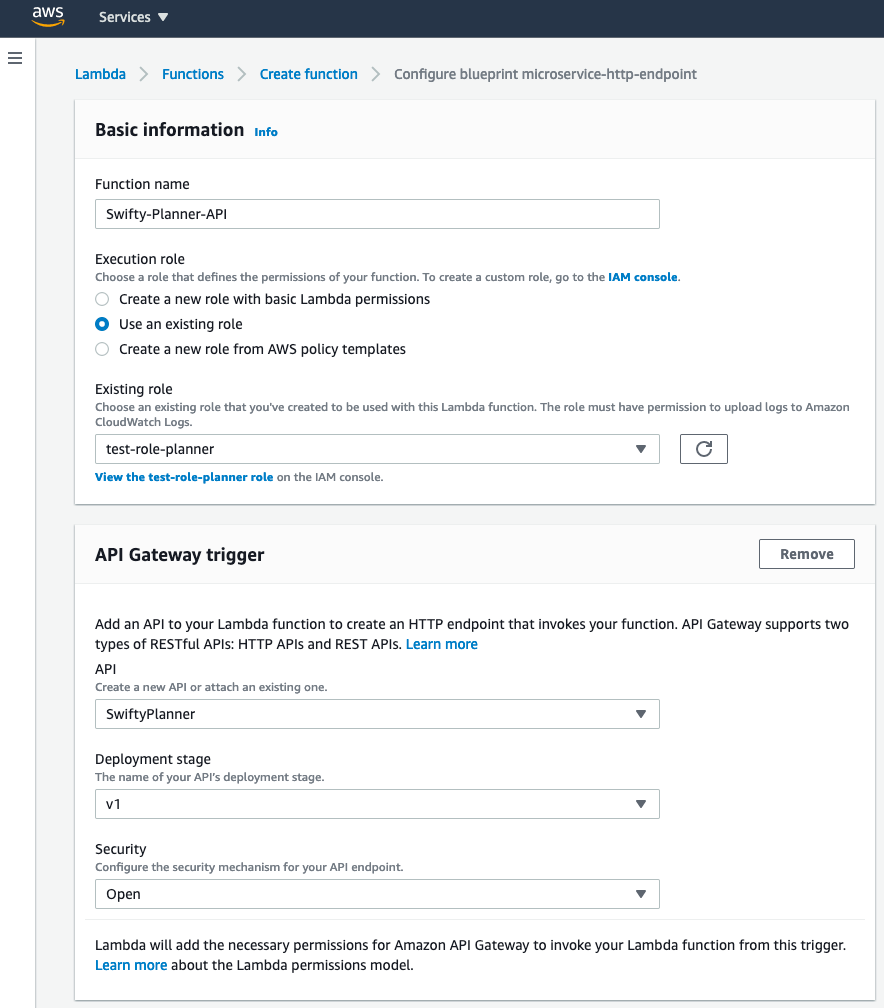
Don't worry about security for now.
Configure Stages and Routes to your Lambdas using Triggers
Since the creation of the lambda created a trigger for the v1 Stage in our API, I'll use that one.
- Go to
Api Gatewayand select Routes, you will have an entry that the Lambda trigger created. - Click on the Method
Anyand then on Route details and click Delete
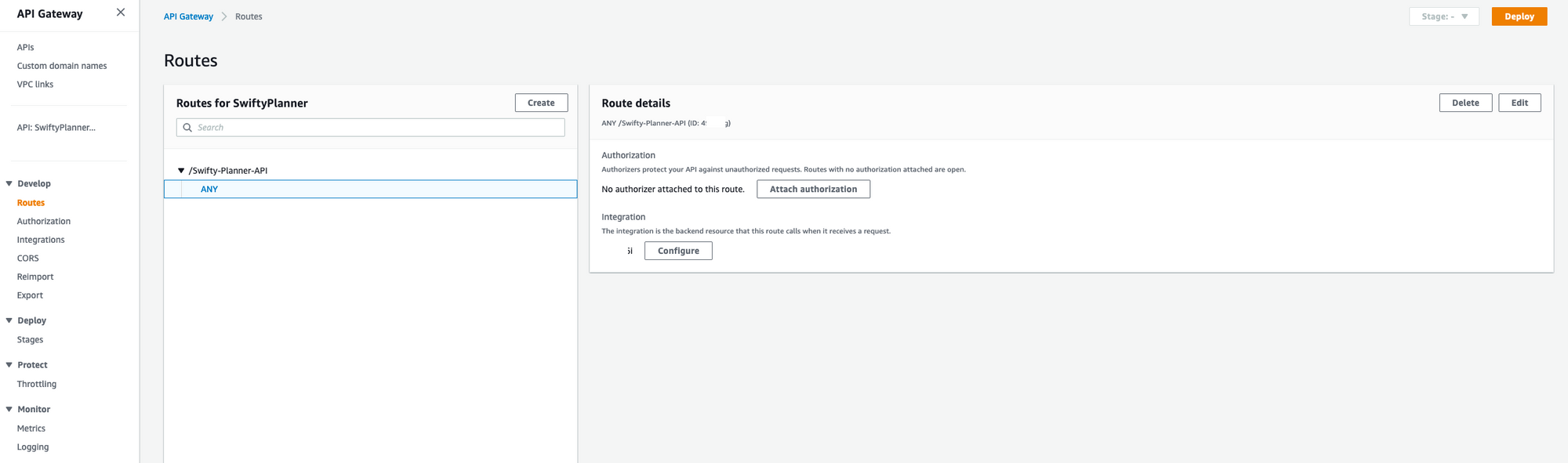
Now create a route v1 like this:
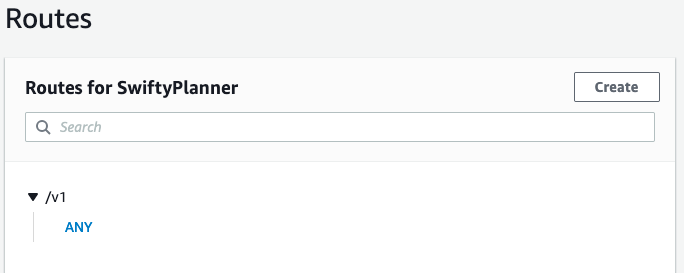
- go to integrations
- select
/v1and unfoldChoose existing integration - Select your lambda trigger and Attach it.
Now you should be able to see the data in www.xxx.com/v1
Last, go to your lambda function and click on Configurations -> Triggers and delete the Trigger that says: The API with ID rvoa2m3y2d doesn’t include a route with path...
You can code the function online in the IDE provided or offline with the following:
- Using AWS SAM CLI
- Uploading manually the zip file with the changes (I'll do this one here because the SAM CLI has a big learning curve)
On your VSC right click the new lambda function and import it into your Github repo folder so you can have the changes in sync, later on I will build a pipeline but for now it's manual.
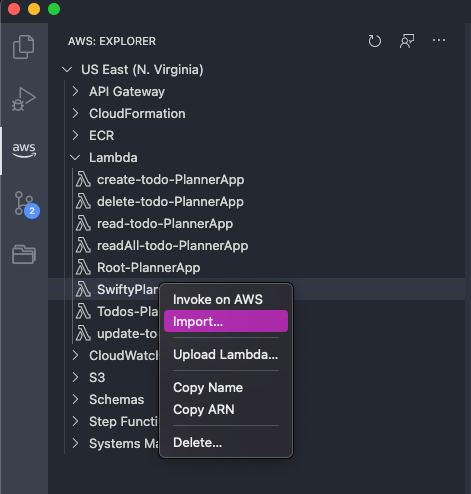
Once you finish your changes, right click the same lambda function and click on Upload Lambda
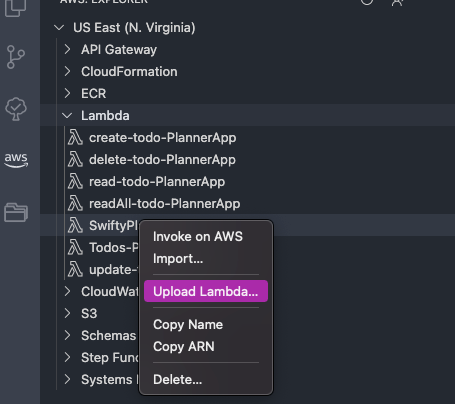
Choose directory and enter inside the folder
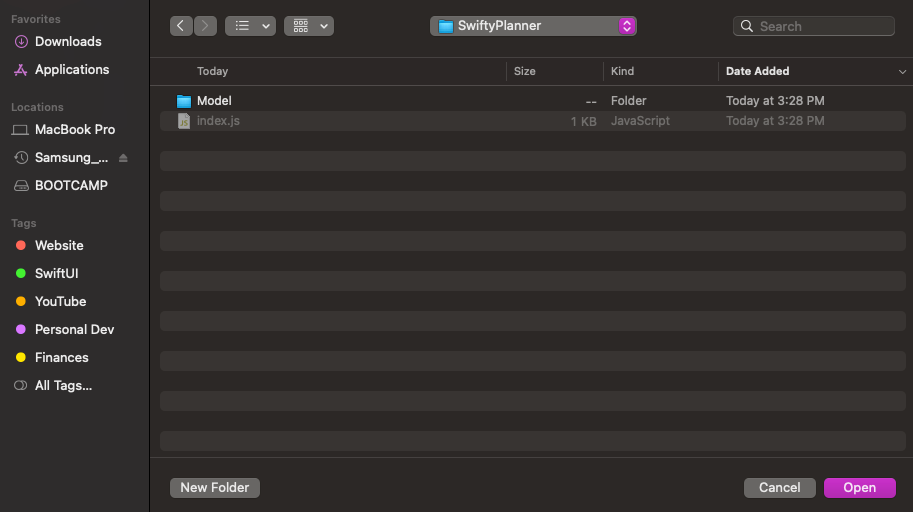
Choose open and on the next prompt choose No because we are not working with AWS SAM now.
You can optionally just upload it to the web in a zip file (don't include the root folder or it will create something like SwiftyPlanner/SwiftyPlanner) and then go to the AWS Lambda page into your Lambda and click Upload.
Clean up - (Optional - this destroys your progress)
To prevent unnecessary costs, delete the resources that you created and will NOT use.
To delete an HTTP API
- Sign in to the API Gateway console at https://console.aws.amazon.com/apigateway.
- On the APIs page, select an API. Choose Actions, and then choose Delete.
- Choose Delete.
To delete a Lambda function
- Sign in to the Lambda console at https://console.aws.amazon.com/lambda.
- On the Functions page, select a function. Choose Actions, and then choose Delete.
- Choose Delete.
To delete a Lambda function's log group
- In the Amazon CloudWatch console, open the Log groups page.
- On the Log groups page, select the function's log group (
/aws/lambda/my-function). Choose Actions, and then choose Delete log group. - Choose Delete.
To delete a Lambda function's execution role
- In the AWS Identity and Access Management console, open the Roles page.
- Select the function's role, for example,
my-function-.31exxmpl - Choose Delete role.
- Choose Yes, delete.
Step 5: Setup the domain you'll use (Optional)
I love CloudFlare and I will use it here. Why?
- AWS charges you for DNS queries
- I don't want to put all the eggs in one basket
- I will use Cloudflare free Certificate keys, security with
DDoS attack mitigationandGlobal Content Delivery Network
I can't express enough my love for Cloudflare and all the good free work they are doing.
- Make sure your DNS records point to Cloudflare
- In Cloudflare, create a new Origin Certificate
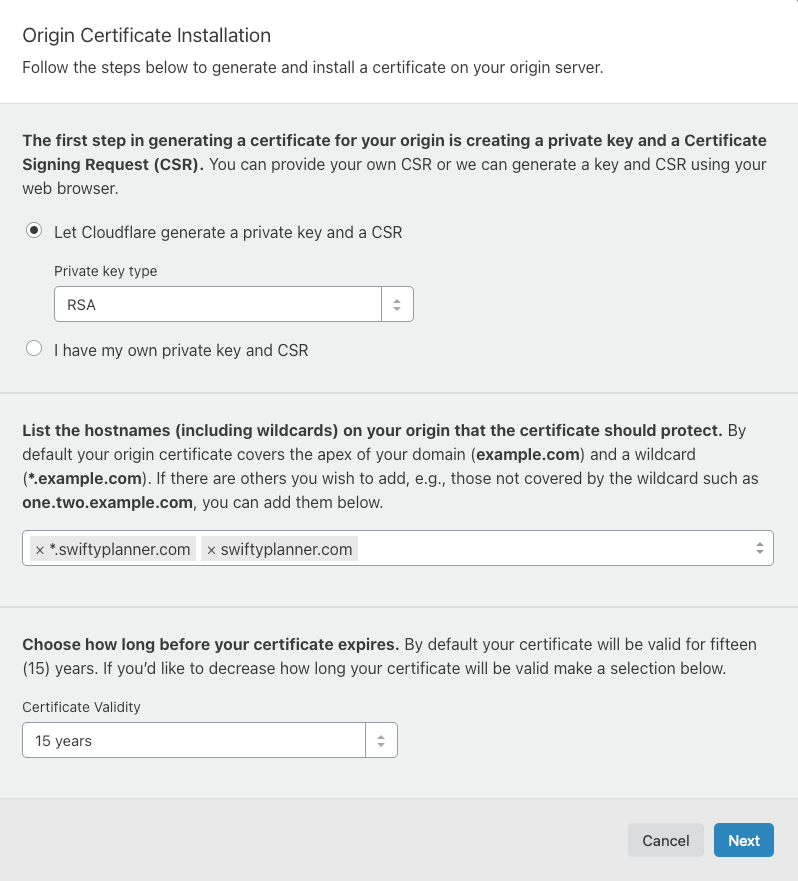
Create offline backups of those keys and also download the .PEM root certificate from Cloudflare.
3. Using the AWS Certificate Manager create a new certificate by Importing the one you created in Cloudflare. Your Certificate Chain will be the root certificate you downloaded above from Cloudflare. If you have any issues importing the certificate look here.
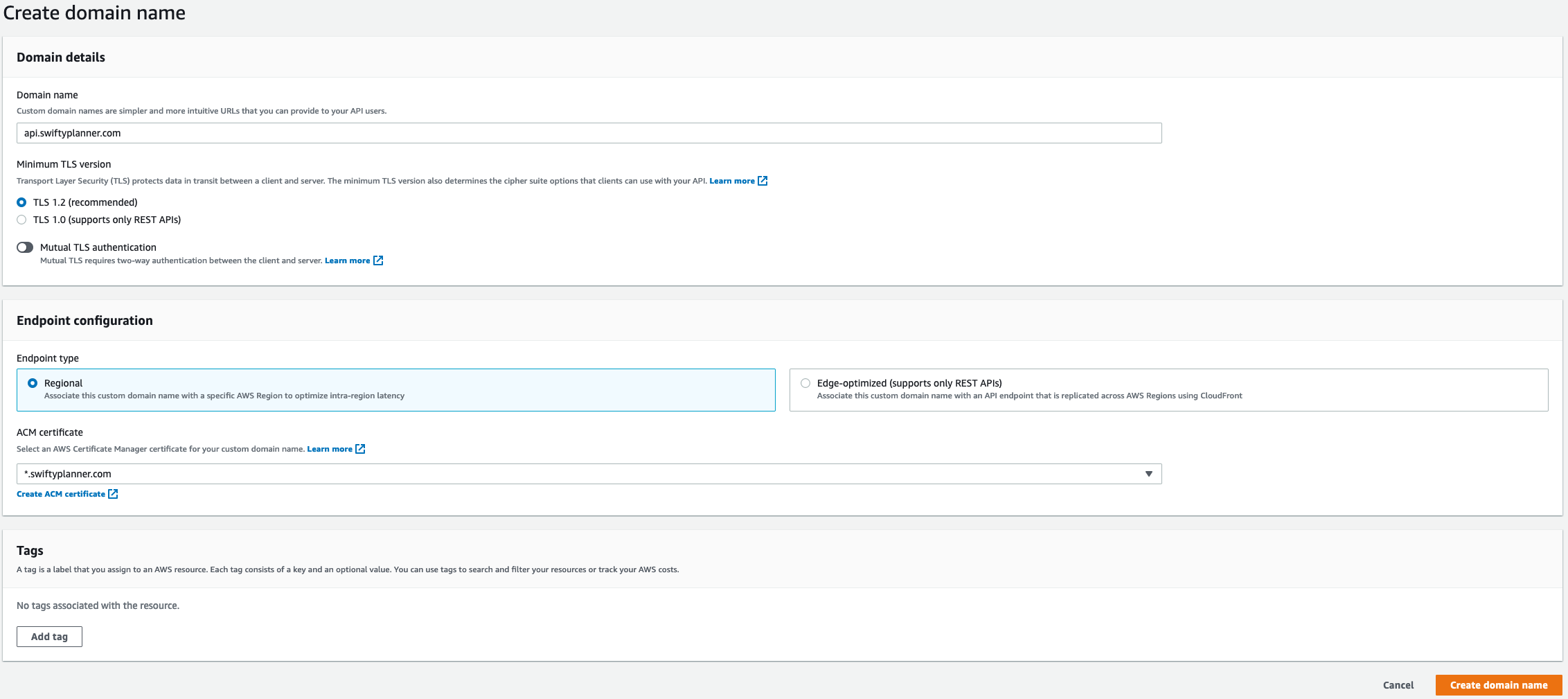
Now that I have the Certificates, go to the API Gateway and click on Custom Domain Names -> Create and this is how it should look:
Now in the same custom domain name tab, click on API mapping to configure one.
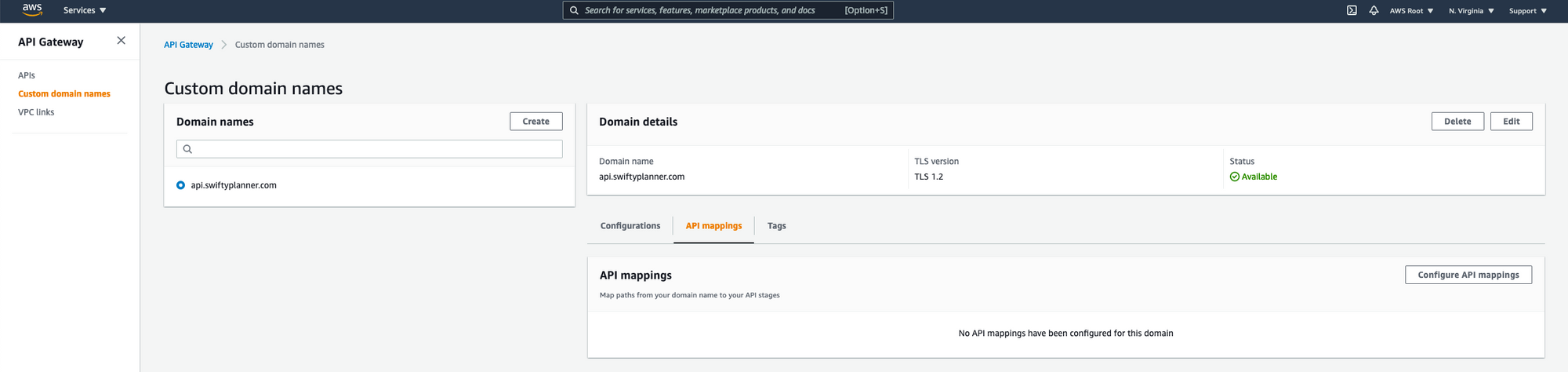
Next select the API created and the desired Stage

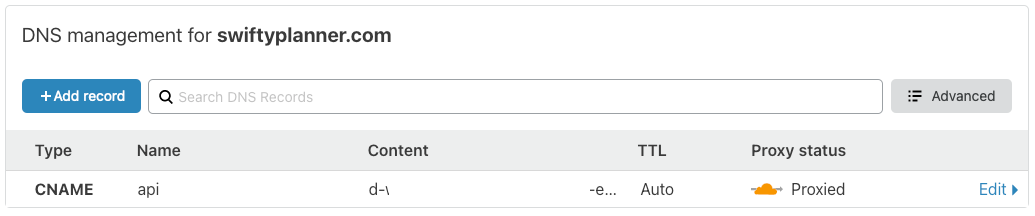
Once created, go to your DNS provider and create a new DNS record, using this config:
- CNAME
- Go to custom domain names in the
API Gateway domain nameand copy the value underEndpoint configuration -> API Gateway domain name, which is a URL to the API (don't copy http//....)
Restrict Data to Domain only
- Go to
API Gateway domain nameand click the name of it in the left sidebar and Click on Edit.

2. Where it says Default endpoint select Disable.
Now when you go to the Amazon URL it won't show the API data.
CRUD operations in DynamoDB using Lambda + API Gateway with Proxy Integration
If you don't follow the above, you'll soon see an internal Server Error in the API and if you go to the logs it'll say:
Error: Error ValidationException: One or more parameter values were invalid: Type mismatch for key X expected: S actual: MThat means that your payload to the API doesn't match the data model you defined in Dynamo. Even though DynamoDB is schemaless, at the table creation you had an ability to specify some Attribute Definitions. They need to be preserved for all the items in the table.
Lambdas and Routes
I will use the recommended new way of doing it by AWS which takes advantage of the native routing functionality available in API Gateway. In many cases, there is no need for the web framework in the Lambda function, which increases the size of the deployment package. API Gateway is also capable of validating parameters, reducing the need for checking parameters with custom code. It can also provide protection against unauthorized access, and a range of other features more suited to be handled at the service level. When using API Gateway this way, the new architecture looks like this:
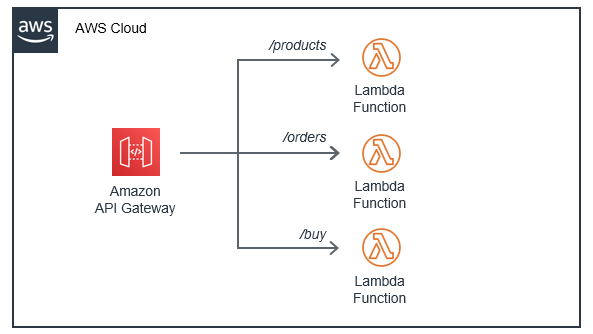
Additionally, the Lambda functions consist of less code and fewer package dependencies. This makes testing easier and reduces the need to maintain code library versions. Different developers in a team can work on separate routing functions independently, and it becomes simpler to reuse code in future projects.
Ignore below this point
Documentation reference
- DynamoDB - From getItem to backups
- Lambda - with Amazon API Gateway
- Lambda function handler in Node.js - This guide is for HTTP API which is the new, cheaper & faster version of REST API, but if you'd like to create a REST API, this is a great example of how to do it.
TODO:
- Create Pipeline to automate dev/depl process of:
- API
- Lambda Functions - User Cloud Formation to create a Streamline flow with a pipeline for future faster Application creation/deployment.
Suggestion to myself:
- Create a test account and Go to Cloud Formation and select upload YAML file.
- The pipeline can be replicated by creating a new lambda function, it will automatically create a pipeline, so get the json from that and see.
- The YAML can be configured from scratch and then the UI editor will show you all the changes to be made. Are are some links: 1, 2, 3.
My research so far...
 Esteban Herrera
Esteban Herrera
 Jonathan BROSSARD
Jonathan BROSSARD

